Query Submission
In NebulaStream, we apply a phased optimization and execution model. Common systems like Common database systems use a two-phase approach, i.e., an optimization phase on logical operators and an execution phase on physical operators. In this model, the query is translated in a DAG of logical operators and then into a DAG of physical operators, which are then deployed. In contrast, in NebulaStream we follow the idea of deep optimization, thus our optimization and execution consist of multiple phases. Each phase takes a DAG as an input, applies optimization and conversion on the node, and outputs a valid DAG of operators. However, we employ a rich set of different operators with different granularity and properties, instead of being restricted to logical and physical operators only.
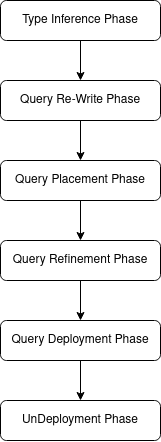
After submitting a query via the rest endpoint and the creation of the query plan, the current version of the phase model inside NebulaStream contains the following phases (please note that we allow an arbitrary set of phases):
- Type Inference Phase: Data types and value ranges are inferred from the attributes used in the query
- Query Re-write Phase: Rule-based query rewriting to the query (e.g., filter push down) is applied
- Query Placement Phase: Operators in the query on the nodes available in the topology are placed
- Query Refinement Phase: Refinement rules to the query (e.g., select a join algorithm or a window strategy) are applied
- Query Deployment Phase: Sub-plans of the query are deployed in the respective node
- This phase includes the serialization, deserialization and the transmission of the sub-plans to the worker.
- RegisterQueryPhase: Query plan is converted into a query execution plan, local optimizations and local algorithm selection are applied, pipelines are generated and compiled
- (Optional): Query Undeploy Phase: Sub-plan from the respective nodes is undeployed