Tutorial
The NebulaStream tutorial demonstrates how to download and configure NebulaStream, how to submit queries to NebulaStream, and visualize their results.
Running example: The NebulaStream smart city (IoTropolis)
The tutorial is based on a smart city scenario, the NebulaStream IoTropolis. In this smart city, wind turbines and solar panels /produce/ energy, whereas households, offices, factories, and street lights /consume/ energy.
Obviously, there must be a balance: if energy production is low, energy consumption must also be limited. For example, in this tutorial, street lights are turned off at night when the wind is slow and wind turbines do not produce enough energy.
NebulaStream is used to gather measurements from energy producers and consumers, aggregate it, compute the difference between produced and consumed energy, and send out a signal that triggers a change of street light usage.
Installation and execution
The tutorial is installed using Docker Compose:
git clone https://github.com/nebulastream/nebulastream-tutorial
cd nebulastream-tutorial
docker compose pull
docker compose up --build
In the last command, --build can be omitted from subsequent restarts of the containers.
TODO: Rename branch when finished
Docker services
The docker-compose.yml file configures and starts the following Docker containers.

- coordinator: This Docker container runs the image
nebulastream/nebulastream-executable-image. This image contains the binaries for both the NebulaStream coordinator and the NebulaStream worker, so we specify a custom entry point to run the coordinator. We also specify a configuration file for the coordinator, which is explained in the section Coordinator configuration.
coordinator:
image: nebulastream/nes-executable-image:latest
entrypoint: "nesCoordinator --configPath=/config/coordinator.yaml"
ports:
- 8081:8081
volumes:
- ./:/tutorial
- producers-worker, consumers-worker-1, consumers-worker-2: The Docker Compose configuration specifies multiple workers, which are configured to retrieve data from various data sources.
These also use the
nebulastream/nebulastream-executable-imageimage with a custom entry point that specifies a worker-specific configuration file. The example below shows the producers-worker; other workers are configured similarly.
producers-worker:
image: nebulastream/nes-executable-image:latest
entrypoint: "nesWorker --configPath=/config/producers-worker.yaml"
depends_on:
- coordinator
volumes:
- ./:/tutorial
datatown: This Docker container provides a 3D visualization of IoTropolis that runs in a web browser. The container also generates data for solar panels, wind turbines, and consumers.
Note: The browser window running the 3D visualization must be open and visible on the screen in order for data to be generated.
datatown:
image: nebulastream/nes-smart-city-image:latest
ports:
- 9003:9003
- ui: This Docker container provides the web-based NebulaStream UI through which users can submit NebulaStream queries, monitor existing queries, and retrieve information about the NebulaStream cluster topology and available data sources.
ui:
image: nebulastream/nes-ui-image:latest
ports:
- 9000:9000
- mosquitto: The tutorial uses Eclipse Mosquitto as an MQTT broker to exchange data between the data generator and the workers. The data generator publishes events from the different energy consumers and producers to different MQTT topics. NebulaStream workers subscribe to these topics as data sources and publish the results of a query to other MQTT topics. The 3D visualization also subscribes to predefined result topics in order to trigger changes in the 3D visualization.
mosquitto:
image: eclipse-mosquitto
ports:
- 1885:1885
- 9001:9001
- 9002:9002
volumes:
- ./config/mosquitto:/mosquitto/config
- grafana: The tutorial also uses Grafana to visualize input data and query results. This container is custum-built with Docker Compose to provision a preinstalled MQTT datasource and custom dashboard for the tutorial.
services:
grafana:
build: ./grafana
restart: unless-stopped
ports:
- 3000:3000
volumes:
- grafana-storage:/var/lib/grafana
volumes:
grafana-storage: {}
A number of Docker services, e.g., the coordinator, the data generator, the UI, Mosquitto, and Grafana, expose ports, so that we can interact with them on the host system.
The coordinator and the worker also mount the folder config/nebulastream, so that we can provide configuration files to the container.
Configuring NebulaStream
A minimal NebulaStream configuration must configure network options, as well as logical and physical sources. Logical sources specify the data schema and are part of the coordinator configuration. Physical sources specify how data is obtained and are part of the worker configuration.
Coordinator configuration
The NebulaStream coordinator is configured through the file coordinator.yaml which is mounted in the Docker container in the folder /config and passed to the --configPath command option:
nesCoordinator --configPath=/config/coordinator.yaml
Further information: NebulaStream documentation: Coordinator Configuration Options
Logging options
The configuration file first specifies a log level:
logLevel: LOG_ERROR
Networking options
Next, we specify network information.
restIp: NebulaStream clients, e.g., the NebulaStream UI or the Java client, interact with the coordinator through a REST API.restIpspecifies the IP address on which the coordinator listens for requests. The value0.0.0.0allows us to access the REST API from the host system.The coordinator also starts an internal worker, for which we have to configure the hostname with the options
coordinatorHostandworker.localWorkerHost. The internal worker sits at the top of the NebulaStream cluster topology. It is also the worker on which sinks are executed.
The hostnames, e.g., coordinator, correspond to the service names in the Docker Compose configuration.
restIp: 0.0.0.0
coordinatorHost: coordinator
worker:
localWorkerHost: coordinator
Logical sources
Next, we configure the logical sources that are known to the coordinator. A logical source represents an stream of input tuples, possibly from multiple sensors, that share common characteristics. A logical has two properties:
logicalSourceName: A unique identifier of the logical source.fields: The schema of the logical source, an unordered list of named and typed attribute.
NebulaStream supports the following data types:
- Signed integers with different bits:
INT8,INT16,INT32,INT64 - Unsigned integers with different bits:
UINT8,UINT16,UINT32,UINT64 - Floating points with different precision:
FLOAT32,FLOAT64 - Booleans:
BOOLEAN - Variable-sized strings:
TEXT
In the tutorial, there are three logical sources: windTurbines, solarPanels, and consumers. The sources windTurbines and solarPanels have the same schema.
logicalSources:
- logicalSourceName: "windTurbines"
fields:
- name: producerId
type: INT8
- name: groupId
type: INT8
- name: producedPower
type: INT32
- name: timestamp
type: UINT64
- logicalSourceName: "solarPanels"
fields:
- name: producerId
type: INT8
- name: groupId
type: INT8
- name: producedPower
type: INT32
- name: timestamp
type: UINT64
- logicalSourceName: "consumers"
fields:
- name: consumerId
type: INT8
- name: sectorId
type: INT8
- name: consumedPower
type: INT32
- name: consumerType
type: TEXT
- name: timestamp
type: UINT64
Note: Fields that encode timestamps which are used in window operations must be UINT64.
Note: Java UDFs only support signed integers, except for UINT64 to support timestamps and window operations.
Further information: NebulaStream documentation: Defining Data Sources
Worker configuration
Each NebulaStream worker is configured through a dedicated configuration file, which are mounted in the Docker container in the folder tutorial and passed to the --configPath command line option. For example, the consumers worker is started as follows:
nesWorker --configPath=/config/consumersWorker.yaml
Further information: NebulaStream documentation: Worker Configuration Options
Logging options
The configuration file first specifies a log level:
logLevel: LOG_ERROR
Network options
Next, we specify network information.
coordinatorHost: Hostname of the coordinator, to which the worker should register upon startup.localWorkerHost: Hostname under which this worker registers with the coordinator.
The hostnames, e.g., coordinator, correspond to the service names in the Docker Compose configuration.
coordinatorHost: coordinator
localWorkerHost: consumers-worker
Physical sources
Next, we specify the physical data sources that are connected to the worker. A physical source connects to a concrete data source. Each physical source is associated with a specific logical source. The tuples provided by the data source have to match the schema of the logical source.
NebulaStream supports reading data from CSV files or from popular message brokers, such es MQTT, Kafka, or OPC, as data sources.
In this tutorial, we use an MQTT broker as the data source for all physical sources.
A physical source is configured with the following options:
logicalSourceName: The name of the associated logical source.physicalSourceName: The unique name of this physical source.type: The type of the data source, e.g.,MQTT_SOURCE.configuration: Type-specific configuration options.
An MQTT source has the following configuration options:
url: The URL of the MQTT broker.topic: The topic to which this physical source should subscribe.
physicalSources:
- logicalSourceName: consumers
physicalSourceName: streetLights
type: MQTT_SOURCE
configuration:
url: ws://mosquitto:9001
topic: streetLights
Further information: NebulaStream documentation: Physical Sources Configuration
Topology of logical and physical sources
Multiple physical sources can be associated with a single logical source, even across multiple NebulaStream workers. A worker can also provide physical sources for different logical sources.
In our setup, we show the following cases:
- The
windTurbinesandsolarPanelslogical sources each have a single physical source, which are configured on theproducersworker. - The
consumerslogical source has four physical sources, which are configured on two physical sources, i.e.,consumers-worker-1andconsumers-worker-2. - On
consumers-worker-2, there are three physical sources configured for theconsumerslogical source.

Visualizing the input data
With Docker containers running, we can already show the generated input data in Grafana:
Open the 3D visualization at http://localhost:9003 to start the data generator.
Note: This window must remain visible, otherwise data generation stops.
Open Grafana at http://localhost:3000. Grafana should open with the NebulaStream dashboard. The panels in the top row show the generated data, which is published on the MQTT topics
windturbines,solarpanels,streetLights,households,offices, andfactories. The panels in the rows below are empty because there is no streaming query running yet in NebulaStream.
Of course, the purpose of NebulaStream is to execute streaming queries. We can submit queries to NebulaStream using the web UI, which we describe next.
The NebulaStream web UI
The NebulaStream web UI can be accessed at http://localhost:9000. It provides the following functionality:
- Query catalog: Submit queries and monitor their status.
- Topology: Visualize the hierarchical network topology of the workers.
- Source catalog: Display information about the defined physical sources.
- Settings: Configure how the coordinator can be configured over the network.
The query catalog
The query catalog shows the queries that are known in the system and their status. For example, a query can be in the status OPTIMIZING, RUNNING, STOPPED, or FAILED.
We can also submit new queries through the query catalog, which we demonstrate in Running NebulaStream queries, and display the execution plan of running queries, which we demonstrate in Query merging.
The topology screen
The topology screen visualizes the topology of the NebulaStream workers. We have defined three workers in the Docker Compose configuration to which we have attached physical sources. These are the nodes 2-4. There is a fourth worker, node 1, which is automatically created by the coordinator.

By default, when I worker registers itself with the coordinator, it will register as a child of the worker created by the coordinator. It is also possible to make hierarchical topologies with intermediate workers using the REST API.
Further information: NebulaStream documentation: Topology REST API.
The source catalog
The source catalog shows information about the logical sources known to the coordinator, i.e., the schema and the connected physical sources. We can also see on which node a physical source resides.

The settings screen
On the settings screen, we can configure the hostname and port of the NebulaStream coordinator to which we want to connect with the UI.
Since the coordinator Docker service is accessible on the host machine, the default values localhost and 8081 should work.
You can verify the connection by clicking on “Save changes”, after which a message “Connected to NebulaStream!” should appear.

Running NebulaStream queries
NebulaStream supports queries with the following operators:
- Basic ETL operations, e.g.,
filter,map,projectandunion - Window aggregations
- Window-based joins of multiple logical sources
- Java UDFs with Map and FlatMap semantics
- TensorFlow Lite UDFs (not discussed in this tutorial)
- Complex event processing operations (not discussed in this tutorial)
Further information: NebulaStream documentation: Query API
Query sources and sinks
Queries are started with the from operator, which reads tuples from
a logical source, and finished with a sink operator, which specifies the
sink that receives the result stream.
NebulaStream supports files as sinks, as well as MQTT, Kafka, or OPC
message brokers.
In the UI, we specify queries as C++ code fragments.
A minimal query, which just copies the tuples from a logical source
to an output sink, looks like this:
// Start a new query by reading from the consumers logical source
Query::from("consumers")
// Data transformations would go here
// Finish the query by sending tuples to an MQTT sink
.sink(MQTTSinkDescriptor::create("ws://mosquitto:9001", "consumers-copy"));
Running queries
To run the query, we open the query catalog of the NebulaStream web UI at http://localhost:9000/querycatalog.
Then we click on the Add Query button, paste the query into the text box, and click submit.
After a moment, the query will show up as OPTIMIZING and later as RUNNING in the list below the text box.

When the query is running, the result tuples are shown in the Grafana panel Q0: Copying source to sink. Note that the 3D visualization must be running to produce the input data for the query.
The query produces tuples which look like this:
{
"consumers$consumedPower": 2187,
"consumers$consumerId": 7,
"consumers$consumerType": "household",
"consumers$sectorId": 3,
"consumers$timestamp": 1719111420932
}
The output contains tuples from all of the physical sources that make up the consumers logical source, i.e., households, offices, etc. The name of each field is now prefixed with the name of the logical source, i.e., consumers, followed by the schema name separator $.
Example queries
Query 1: Filter tuples
Query 1 uses the filter operator to filter the tuples of the consumers logical source where the value of the attribute consumedPower is greater than 10000.
Query::from("consumers")
.filter(Attribute("consumedPower") >= 400)
.sink(MQTTSinkDescriptor::create("ws://mosquitto:9001", "q1-results"));
When we run this query in the UI, the filtered tuples are shown in the Grafana panel Q1: Filter tuples.
Query 2: Filter over multiple attributes
We can also filter over multiple attributes, by combining the predicates with &&:
Query::from("consumers")
.filter(Attribute("consumedPower") >= 400 && Attribute("sectorId") == 1)
.sink(MQTTSinkDescriptor::create("ws://mosquitto:9001", "q2-results"));
The result tuples are shown in the Grafana panel Q2: Filter over multiple attributes.
Query 3: Filter with complex expressions
In general, the filter operator evaluates a complex expression consisting of Attribute("name") terms, boolean operators (&& and ||) and arithmetic operations.
The following query contains these building blocks:
Query::from("consumers")
.filter(Attribute("consumedPower") >= 1 && Attribute("consumedPower") < 60 + 1)
.sink(MQTTSinkDescriptor::create("ws://mosquitto:9001", "q3-results"));
The result tuples are shown in the Grafana panel Q3: Filter with complex expressions.
Further information: NebulaStream documentation: Expressions.
Query 4: Transform data
The map operator assigns the result of a (complex) expression to an attribute.
Similarly to the filter operator, the expression can consist of Attribute("name") terms, boolean operators (&& and ||) and arithmetic operations, and arithmetic functions.
If the specified attribute already exists in the tuple, its contents are overwritten.
Otherwise, the schema of the tuple is extended to contain the new attribute.
The following query, overwrites the value of the attribute consumedPower with the result of dividing it by 1000.
Query::from("consumers")
.map(Attribute("consumedPower") = Attribute("consumedPower") / 1000)
.sink(MQTTSinkDescriptor::create("ws://mosquitto:9001", "q4-results"));
The result tuples are shown in the Grafana panel Q4: Transform data with map.
Further information: NebulaStream documentation: Expressions.
Query 5: Union of multiple queries
The unionWith operator combines the tuples from two queries into a single query.
Both queries must produce tuples with the same query.
The following query combines the tuples from the windTurbines and solarPanels logical source
Query::from("windTurbines")
.unionWith(Query::from("solarPanels"))
.sink(MQTTSinkDescriptor::create("ws://mosquitto:9001", "q5-results"));
The query produces tuples which look like this:
{
"windTurbines$groupId": 3,
"windTurbines$producedPower": 526,
"windTurbines$producerId": 11,
"windTurbines$timestamp": 1719756000981
}
The schema portion of the result tuples is taken from the logical source of the first query, i.e., windTurbines.
The result tuples are shown in the Grafana panel Q5: Union of multiple queries.
Query 6: Enrich tuples with data
In the output of query 5, we cannot distinguish the original source of the tuples.
We can use map to enrich the data with additional source attribute before combining them.
The map operator is applied to both input queries of the unionWith operator.
Query::from("windTurbines")
.map(Attribute("source") = 1)
.unionWith(Query::from("solarPanels")
.map(Attribute("source") = 2))
.sink(MQTTSinkDescriptor::create("ws://mosquitto:9001", "q6-results"));
The query produces tuples which look like this:
{
"windTurbines$source": 2,
"windTurbines$groupId": 0,
"windTurbines$producedPower": 0,
"windTurbines$producerId": 5,
"windTurbines$timestamp": 1719095940092
}
The result tuples are shown in the Grafana panel Q6: Enrich tuples with map.
Query 7: Window aggregations with tumbling windows
The window operator slices the tuple stream into discrete windows and then computes one or more aggregates of the tuples stream.
The aggregations can optionally be grouped by one or more key attributes.
NebulaStream supports time-based tumbling windows and sliding windows, where the time information is taken from a stream attribute, as well as data-based threshold windows.
The following query uses a tumbling window of size 1 hour to compute the total produced energy for each group of solar panels.
The time information is taken from the attribute timestamp of the solarPanels logical source.
Query::from("solarPanels")
.window(TumblingWindow::of(EventTime(Attribute("timestamp")), Hours(1)))
.byKey(Attribute("groupId"))
.apply(Sum(Attribute("producedPower")))
.sink(MQTTSinkDescriptor::create("ws://mosquitto:9001", "q7-results"));
The query produces tuples which look like this:
{
"solarPanels$end": 1719378000000,
"solarPanels$groupId": 3,
"solarPanels$producedPower": 7468,
"solarPanels$start": 1719374400000
}
The attributes start and end indicate the start and end timestamps of the windows. The other attributes are the grouping attribute groupId and the aggregated value of producedPower.
The result of the query is visualized in the Grafana panel Q7: Tumbling windows.
There are four groups of solar panels, which are represented by different colors.
Note that the 3D visualization must be visible on the screen, so that time advances in the data generator.

Query 8: Window aggregations with sliding windows
Query 7 is updated every hour (in the time of the 3D visualization). To update the data more frequently, we can use the sliding window, such as in the following query uses a sliding window of size 1 hour and slide 10 minutes:
Query::from("solarPanels")
.window(SlidingWindow::of(EventTime(Attribute("timestamp")), Hours(1), Minutes(10)))
.byKey(Attribute("groupId"))
.apply(Sum(Attribute("producedPower")))
.sink(MQTTSinkDescriptor::create("ws://mosquitto:9001", "q8-results"));
The result of the query is visualized in the Grafana panel Q8: Sliding windows. In contrast to query Q7, where the X axis has a granularity of one hour, the X axis in query Q8 has a granularity of ten minutes.

Query 9: Join query
The joinWith operator performs a window-based join of two input queries.
The following query computes the difference between produced power and consumed power in each hour.
In addition to joinWith, it also uses the unionWith, window, and map operators.
- First, we combine the
windTurbinesandsolarPanelslogical sources to create a stream of tuples containing all energy producers. - Then we apply a sliding window of size 1 hour and slide 10 minutes to compute the sum of produced energy. This operator produces a single tuple representing the total energy output every 10 minutes.
- We apply a similar sliding window to the
consumerslogical source. - Finally, we join both the producers stream and the consumers stream.
We use the same sliding window definition as in the input streams, using the attribute
startof the input streams. This ensures that only one tuple is contained in each the windows of the input streams. We therefore use a join expression that evaluates to true to join them. - Finally, we use
mapto compute the difference of the produced and consumed power and assign it to a new attributeDifferenceProducedConsumedPower.
Query::from("windTurbines")
.unionWith(Query::from("solarPanels"))
.window(TumblingWindow::of(EventTime(Attribute("timestamp")), Hours(1)))
.apply(Sum(Attribute("producedPower")))
.map(Attribute("JoinKey") = 1)
.joinWith(Query::from("consumers")
.window(TumblingWindow::of(EventTime(Attribute("timestamp")), Hours(1)))
.apply(Sum(Attribute("consumedPower")))
.map(Attribute("JoinKey") = 1))
.where(Attribute("JoinKey") == Attribute("JoinKey"))
.window(TumblingWindow::of(EventTime(Attribute("start")), Hours(1)))
.map(Attribute("DifferenceProducedConsumedPower") = Attribute("producedPower") - Attribute("consumedPower"))
.sink(MQTTSinkDescriptor::create("ws://mosquitto:9001", "q9-results"));
The query produces tuples which look like this:
{
"consumers$JoinKey": 1,
"consumers$consumedPower": 626607,
"consumers$end": 1719198000000,
"consumers$start": 1719194400000,
"windTurbines$JoinKey": 1,
"windTurbines$end": 1719198000000,
"windTurbines$producedPower": 33796,
"windTurbines$start": 1719194400000,
"windTurbinesconsumers$DifferenceProducedConsumedPower": -592811,
"windTurbinesconsumers$end": 1719198000000,
"windTurbinesconsumers$start": 1719194400000
}
The fields starting with consumers$ and windTurbines$ are taken from the tuples of the right-hand side and left-hand side of the join, respectively. The fields windTurbinesconsumers$start and windTurbinesconsumers$end encode the range of the join window. The field windTurbinesconsumers$DifferenceProducedConsumedPower is produced by the last map operator.
The result of the query is visualized in the Grafana panel Q9: Join. Note that the 3D visualization must be visible on the screen, so that time advances in the data generator.

Actuating events in the 3D smart city
We now have everything we need to construct an end-to-end query pipeline, which takes the data generated form the smart city, performs a computation on it with NebulaStream, and produces an output stream, which triggers an event in the smart city.
Displaying energy produced by solar panels and wind turbines
The first actuation query uses the query Q8 to display the amount of produced power on labels next to the solar panels and wind turbines in the smart city.
To do so, we adapt the query to send the result tuples to the MQTT topics solarPanelDashboards and windTurbineDashboards, respectively:
Query::from("solarPanels")
.window(TumblingWindow::of(EventTime(Attribute("timestamp")), Hours(1)))
.byKey(Attribute("groupId"))
.apply(Sum(Attribute("producedPower")))
.sink(MQTTSinkDescriptor::create("ws://mosquitto:9001", "solarPanelDashboards"));
Query::from("windTurbines")
.window(TumblingWindow::of(EventTime(Attribute("timestamp")), Hours(1)))
.byKey(Attribute("groupId"))
.apply(Sum(Attribute("producedPower")))
.sink(MQTTSinkDescriptor::create("ws://mosquitto:9001", "windTurbineDashboards"));
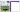
Turning street lights on and off at night depending on available wind speed
The second actuation query uses query Q9 to trigger changes in the street lights at night.
Because the sun is not shining, all of the available energy is produced by the wind turbines.
If wind speed is low, and the difference between produced and consumed energy is too small, a progressively larger number of street lights are turned off.
To trigger these changes, we adapt the query Q9 to send the result tuples to the MQTT topic differenceProducedConsumedPower.
Query::from("windTurbines")
.unionWith(Query::from("solarPanels"))
.window(TumblingWindow::of(EventTime(Attribute("timestamp")), Hours(1)))
.apply(Sum(Attribute("producedPower")))
.map(Attribute("JoinKey") = 1)
.joinWith(Query::from("consumers")
.window(TumblingWindow::of(EventTime(Attribute("timestamp")), Hours(1)))
.apply(Sum(Attribute("consumedPower")))
.map(Attribute("JoinKey") = 1))
.where(Attribute("JoinKey") == Attribute("JoinKey"))
.window(TumblingWindow::of(EventTime(Attribute("start")), Hours(1)))
.map(Attribute("DifferenceProducedConsumedPower") = Attribute("producedPower") - Attribute("consumedPower"))
.sink(MQTTSinkDescriptor::create("ws://mosquitto:9001", "differenceProducedConsumedPower"));
We can control the wind speed using the control panel in the 3D visualization. For example, with wind speed 5, all street lights are illuminated throughout the night. With wind speed 4, a number of street lights are turned of during the night. It is also possible to reduce the rendering speed of the 3D visualization.
The Java client
So far, we have used the web UI to interact with NebulaStream. In the background, the web UI communicates with the NebulaStream coordinator using a REST API. We can also use other clients to interact with NebulaStream. The Java client is the most fully-featured NebulaStream client.
Further information:
Runtime API
The Java client uses an instance of the NebulaStreamRuntime object to encapsulate a connection to a NebulaStream coordinator:
NebulaStreamRuntime nebulaStreamRuntime = NebulaStreamRuntime.getRuntime("localhost", 8081);
The NebulaStreamRuntime instance provides methods to interact with NebulaStream.
The most important methods are:
readFromSource: Create a query by reading tuples from a logical source, similarly toQuery::fromin the C++ syntax used in the web UI.executeQuery: Submit a query to the coordinator.getQueryStatus: Retrieve the status of a query.stopQuery: Stop a query.
Below is an example of how to create, run, and stop the query Q1 in the Java client:
// Create a NebulaStream runtime and connect it to the NebulaStream coordinator.
NebulaStreamRuntime nebulaStreamRuntime = NebulaStreamRuntime.getRuntime("localhost", 8081);
// Process only those tuples from the `consumers` logical source where `consumedPower` is greater than 10000.
Query query = nebulaStreamRuntime.readFromSource("consumers")
.filter(attribute("consumedPower").greaterThan(10000));
// Finish the query with a sink.
query.sink(new MQTTSink("ws://mosquitto:9001", "q1-results", "user", 1000,
MQTTSink.TimeUnits.milliseconds, 0, MQTTSink.ServiceQualities.atLeastOnce, true));
// Submit the query to the coordinator.
int queryId = nebulaStreamRuntime.executeQuery(query, "BottomUp");
// Wait until the query status changes to running
for (String status = null;
!Objects.equals(status, "RUNNING");
status = nebulaStreamRuntime.getQueryStatus(queryId)) {
System.out.printf("Query id: %d, status: %s\n", queryId, status);
Thread.sleep(1000);
};
// Let the query run for 10 seconds
for (int i = 0; i < 10; ++i) {
String status = nebulaStreamRuntime.getQueryStatus(queryId);
System.out.printf("Query id: %d, status: %s\n", queryId, status);
Thread.sleep(1000);
}
// Stop the query
nebulaStreamRuntime.stopQuery(queryId);
// Wait until the query has stopped
for (String status = null;
!Objects.equals(status, "STOPPED");
status = nebulaStreamRuntime.getQueryStatus(queryId)) {
System.out.printf("Query id: %d, status: %s\n", queryId, status);
Thread.sleep(1000);
};
Query API
In Java, we cannot use overloaded operators to form complex expression as we do in the C++ syntax. Instead, we use a fluid syntax to chain operators.
Fluid syntax examples
For example, query Q1 contains the following expression:
Attribute("producedPower") <= 400
In the Java client, we formulate this expression as follows:
attribute("producedPower").lessThanOrEqual(400)
In general, an operation LHS op RHS in C++ syntax is converted to LHS.opMethod(RHS) in Java syntax.
Expressions starting with numbers or boolean literals must wrap the left hand side in a literal method.
For example, 1 + 2 in C++ syntax becomes literal(1).add(2) in Java.
Breaking up queries
The fluid query API of the Java client allows us to break up complex queries into smaller components.
The following is literal translation of query Q9 in Java.
Query query = nebulaStreamRuntime.readFromSource("windTurbines")
.unionWith(nebulaStreamRuntime.readFromSource("solarPanels"))
.window(SlidingWindow.of(eventTime("timestamp"), hours(1), minutes(10)))
.apply(sum("producedPower"))
.map("JoinKey", literal(1))
.joinWith(nebulaStreamRuntime.readFromSource("consumers")
.window(SlidingWindow.of(eventTime("timestamp"), hours(1), minutes(10)))
.apply(sum("consumedPower"))
.map("JoinKey", literal(1)))
.where(attribute("JoinKey").equalTo(attribute("JoinKey")))
.window(SlidingWindow.of(eventTime("start"), hours(1), minutes(10)))
.map("DifferenceProducedConsumedPower",
attribute("producedPower").subtract(attribute("consumedPower")));
Instead of writing it as one big statement, we can also break it up as follows:
Query windTurbines = nebulaStreamRuntime.readFromSource("windTurbines");
Query solarPanels = nebulaStreamRuntime.readFromSource("solarPanels");
Query producers = windTurbines.unionWith(solarPanels)
.window(SlidingWindow.of(eventTime("timestamp"), hours(1), minutes(10)))
.apply(sum("producedPower"))
.map("JoinKey", literal(1)));
Query consumers = nebulaStreamRuntime.readFromSource("consumers")
.window(SlidingWindow.of(eventTime("timestamp"), hours(1), minutes(10)))
.apply(sum("consumedPower"))
.map("JoinKey", literal(1));
Query joined = producers
.joinWith(consumers)
.where(attribute("JoinKey").equalTo(attribute("JoinKey")))
.window(SlidingWindow.of(eventTime("start"), hours(1), minutes(10)));
Query difference = joined.map("DifferenceProducedConsumedPower",
attribute("producedPower").subtract(attribute("consumedPower")));
Query examples
The repository contains Java versions of the previous example queries in the folder java-client-example.
These can be run individually from an IDE or all queries at once, using ./gradlew run.
Query Q1 stops after running for 10 seconds to demonstrate the runtime API of the NebulaStreamRuntime object.
The other queries have to be stopped manually.
Java UDFs
When we execute NebulaStream queries from the Java client, we can also use Java UDFs to transform data.
NebulaStream supports to UDF-based operators: map and flatMap.
UDFs can contain arbitrary Java code, and the code dependencies of the UDF are automatically transferred from the Java client to the workers, including third-party libraries.
The UDF method signature depends on the schema of the input tuples and determines the schema of the output tuples.
Map UDFs
The Map Java UDF operator applies a stateless UDF to each input tuple and produces exactly one output tuple.
Because it is stateless, it can be pushed down to data sources to reduce the amount of transferred data.
A Map UDF implements the MapFunction interface, where IN and OUT are class parameters representing the input and output schema, respectively.
class MyMapFunction implements MapFunction<IN, OUT> {
public OUT map(final IN consumersInput) {
OUT out = new OUT();
// ...
return out;
}
}
The UDF can then be used in queries as follows:
Query query = nebulaStreamRuntime.readFromSource("...")
.map(new MyMapFunction());
FlatMap UDFs
The FlatMap Java UDF operator applies a stateful UDF to each input tuple and produces a collection of zero or more results.
Any instance variable of the UDF class will retain its state accross multiple invocations of the UDF on different tuples.
The operator therefore enables us to express an arbitrary computation over multiple tuples.
A FlatMap UDF implements the FlatMapFunction interface, where IN and OUT are class parameters representing the input and output schema, respectively.
class MyFlatMapFunction implements FlatMapFunction<IN, OUT> {
private Map state = new HashMap(); // Can be any instance variable
public Collection<OUT> map(final IN consumersInput) {
List<OUT> out = new ArrayList<>();
out.append(new OUT());
// ...
return out;
}
}
The UDF can then be used in queries as follows:
Query query = nebulaStreamRuntime.readFromSource("...")
.flatMap(new MyFlatMapFunction());
Input type mapping
The input type of the UDF must match the schema of the input tuples.
Concretely, we have to match the bit length of the attributes, i.e., an INT8 attribute is mapped to the Java type byte, an INT16 attribute is mapped to a short field, and so on.
Because Java types are signed, we also have to use signed types, e.g., INT8 instead of UINT8
The only exception to this rule are UINT64 attribures, which can represent timestamps, and are mapped to the Java type long.
For example, the consumers logical source is defined as follows:
- logicalSourceName: consumers
fields:
- name: consumerId
type: INT8
- name: sectorId
type: INT8
- name: consumedPower
type: INT32
- name: consumerType
type: TEXT
- name: timestamp
type: UINT64
It is mapped to the following Java class (the order of the fields does not matter):
class ConsumersInput {
byte consumerId;
byte sectorId;
int consumedPower;
String consumerType;
long timestamp;
}
UDF example
The class JavaUdfExampleQuery converts a UINT64 timestamp attribute to a human-readable form and extends the input tuples with it.
Because the schema of the output stream is determined by the output type of the UDF, we also have to copy the input values.
class ConvertTimestampToDateTime implements MapFunction<ConsumersInput, Output> {
@Override
public Output map(final ConsumersInput consumersInput) {
// Copy fields of the input stream into the output
Output output = new Output();
output.consumerId = consumersInput.consumerId;
output.sectorId = consumersInput.sectorId;
output.consumedPower = consumersInput.consumedPower;
output.consumerType = consumersInput.consumerType;
output.timestamp = consumersInput.timestamp;
// Convert the UINT64 input timestamp into a human-readable form
Date date = new Date(consumersInput.timestamp);
output.datetime = date.toString();
// Return the output object
return output;
}
}
Query merging
Query merging is an important feature of NebulaStream which aims to reduce redundant computation and data transfers in multi-user environment. We demonstrate query merging with the following queries:
Query 1: Filter before map
Query::from("windTurbines")
.filter(Attribute("producedPower") < 80000)
.map(Attribute("producedPower") = Attribute("producedPower") / 1000)
.sink(MQTTSinkDescriptor::create("ws://mosquitto:9001", "q1-merged-results"));
Query 2: Map before filter
Query::from("windTurbines")
.map(Attribute("producedPower") = Attribute("producedPower") / 1000)
.filter(Attribute("producedPower") < 80)
.sink(MQTTSinkDescriptor::create("ws://mosquitto:9001", "q2-merged-results"));
These queries are semantically equivalent but syntactically different.
- The order of the
filterandmapoperator is switched. - In the second query, the attribute
producedPoweris compared against 80 instead of 80000, to account for the division by 1000 in the precedingmapoperation.
By default, NebulaStream does not use query merging.
This is reflected in the execution plans of both queries.
We can show these execution plans by clicking on Show details in the
web UI query catalog, selecting the tree icon on the right, and then
selecting Execution plan from the drop down box.
Each query has its own query plan running on the node to which the
windTurbines physical source is attached.

Query plan for query 1:
SINK(opId: 9, statisticId: 0: {NetworkSinkDescriptor{Version=0;Partition=1::8::0::0;NetworkSourceNodeLocation=tcp://coordinator:33449}})
|--MAP(opId: 7, statisticId: 13, predicate: FieldAccessNode(windTurbines$producedPower[INTEGER(32 bits)])=FieldAccessNode(windTurbines$producedPower[INTEGER(32 bits)])/ConstantValue(BasicValue(1000)))
| |--FILTER(opId: 6, statisticId: 12, predicate: FieldAccessNode(windTurbines$producedPower[INTEGER(32 bits)])<ConstantValue(BasicValue(80000)))
| | |--SOURCE(opId: 5, statisticId: 3, originid: 1, windTurbines,LogicalSourceDescriptor(windTurbines, windTurbines))
Query plan for query 2:
SINK(opId: 22, statisticId: 0: {NetworkSinkDescriptor{Version=0;Partition=2::21::0::0;NetworkSourceNodeLocation=tcp://coordinator:33449}})
|--MAP(opId: 20, statisticId: 20, predicate: FieldAccessNode(windTurbines$producedPower[INTEGER(32 bits)])=FieldAccessNode(windTurbines$producedPower[INTEGER(32 bits)])/ConstantValue(BasicValue(1000)))
| |--FILTER(opId: 19, statisticId: 19, predicate: FieldAccessNode(windTurbines$producedPower[INTEGER(32 bits)])/ConstantValue(BasicValue(1000))<ConstantValue(BasicValue(80)))
| | |--SOURCE(opId: 18, statisticId: 3, originid: 1, windTurbines,LogicalSourceDescriptor(windTurbines, windTurbines))
Note that even though the FILTER operator was pushed down in query
2, the query plans are different because the operators in these query
plans have different IDs. For example, the MAP operator has ID 7 in
the query 1 and ID 20 in query 2.
To turn on query merging, we have to specify a configuration option in the coordinator configuration.
optimizer:
queryMergerRule: "Z3SignatureBasedCompleteQueryMergerRule"
We have to restart the coordinator for the configuration change to take effect.
When we now submit the two queries again, NebulaStream will realize
that these queries process tuples from the same logical source and
will optimize them together.
Notice how the status of both queries briefly changes to OPTIMIZING
when submitting the second query.
Afterwards, both queries share a query plan.
SINK(opId: 26, statisticId: 0: {NetworkSinkDescriptor{Version=0;Partition=1::25::0::0;NetworkSourceNodeLocation=tcp://coordinator:46209}})
|--MAP(opId: 9, statisticId: 13, predicate: FieldAccessNode(windTurbines$producedPower[INTEGER(32 bits)])=FieldAccessNode(windTurbines$producedPower[INTEGER(32 bits)])/ConstantValue(BasicValue(1000)))
| |--FILTER(opId: 8, statisticId: 12, predicate: ConstantValue(BasicValue(80000))>FieldAccessNode(windTurbines$producedPower[INTEGER(32 bits)]))
| | |--SOURCE(opId: 7, statisticId: 5, originid: 1, windTurbines,LogicalSourceDescriptor(windTurbines, windTurbines))
SINK(opId: 28, statisticId: 0: {NetworkSinkDescriptor{Version=0;Partition=1::27::0::0;NetworkSourceNodeLocation=tcp://coordinator:46209}})
|--MAP(opId: 9, statisticId: 13, predicate: FieldAccessNode(windTurbines$producedPower[INTEGER(32 bits)])=FieldAccessNode(windTurbines$producedPower[INTEGER(32 bits)])/ConstantValue(BasicValue(1000)))
| |--FILTER(opId: 8, statisticId: 12, predicate: ConstantValue(BasicValue(80000))>FieldAccessNode(windTurbines$producedPower[INTEGER(32 bits)]))
| | |--SOURCE(opId: 7, statisticId: 5, originid: 1, windTurbines,LogicalSourceDescriptor(windTurbines, windTurbines))
Note that only the two SINK operators have different IDs (26 and 28) because
they send the result to different MQTT topics.
The other operators have the same operator IDs in both queries, e.g.,
the MAP operator has ID 9.
